Minimal Natural Instruction Structural Transformation | Bucket CTF 2023
Writing a decoder for an autoencoder trained on the MNIST dataset!
OMG MNIST

Files:
Exploration
We are given the h5 file for the encoder part of the autoencoder which contains the model architecture and weights for the encoder. The model architecture is as below:
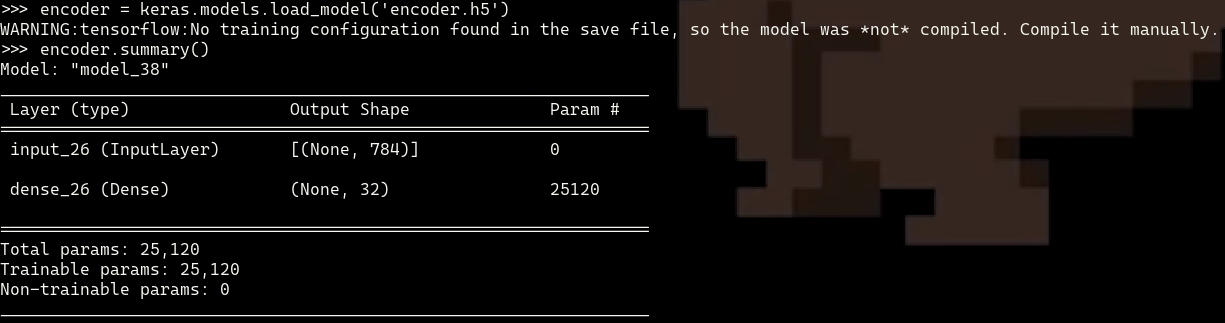
Since the encoder consists of a single dense layer mapping 784 dimensions to 32 dimensions, the decoder should be a single layer mapping 32 dimensions to 784 dimensions.
I searched up how to make an autoencoder in keras and found an official tutorial. The tutorial uses the mnist dataset which has images with dimensions of 28x28 pixels which is 784 total pixels (the input dimension to the encoder).
Training
Following the tutorial to train the model and modifying it to take in a pre-trained encoder, I ended up with following code:
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras.datasets import mnist
import numpy as np
with tf.device('/CPU:0'):
encoder = keras.models.load_model("encoder.h5")
encoder.trainable = False # freeze encoder layer
decoder = keras.models.Sequential([keras.Input(shape=(32,)), keras.layers.Dense(784, activation="sigmoid")])
autoencoder = keras.models.Sequential([encoder, decoder])
autoencoder.summary()
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
# save decoder model for decoding the data
decoder.save("decoder.h5")
When I ran it, each epoch took approximately 1 second and the final train loss was .0923 and the validation loss was .0912. As these losses are very small, we can be confident that the decoder is properly converting the 32-dimensional data back into the image.
Flag
I wrote the following script to decode each letter and show the image of the letter. I chose this approach instead of writing a classification model on top of the encoder to automatically tell me the digit because I thought that there might be some images that are not the digits 0-9, but it turns out all the images are of a digit.
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras.datasets import mnist
import numpy as np
with open("outputs.txt", "r") as fin:
dd = [np.array([*bytes.fromhex(d)]) for d in fin.read().split("\n")]
with tf.device('/CPU:0'):
decoder = keras.models.load_model("decoder.h5")
for d in dd:
img = decoder.predict(np.array([d]))
img.resize((28, 28))
plt.imshow(img)
plt.show()
When I ran this script I was shown an image (like the one below) and asked @burturt to record the digit that pops up. I can quickly go through each digit by pressing alt+f4 which closes the plt.show() window and shows me the next digit.
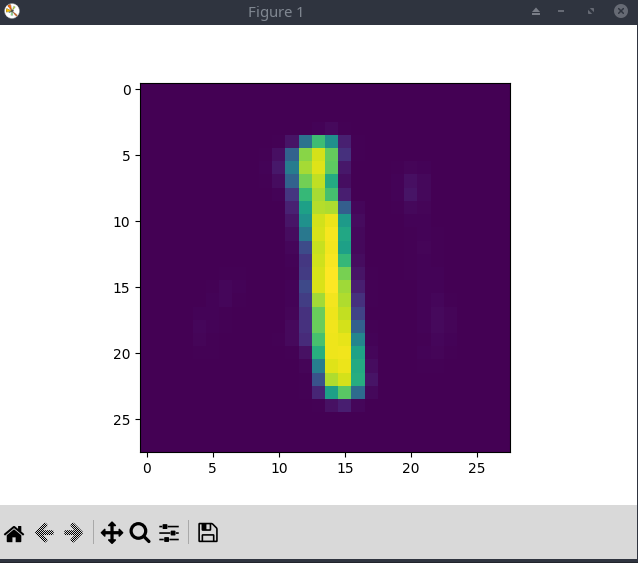
The digits come out to
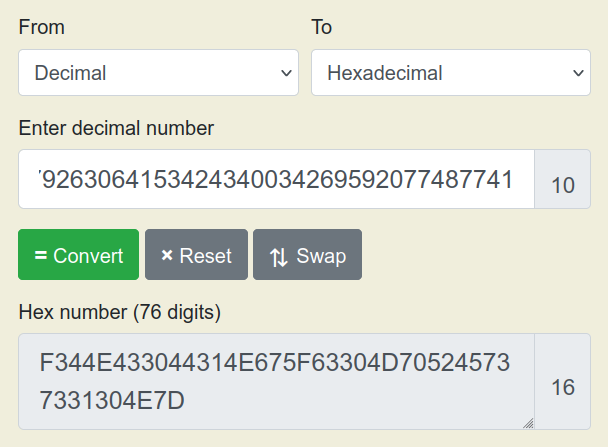
12535225312911299122717464113299622441425155896321480584479263064153424340034269592077487741
We first convert it to hex and then to ascii
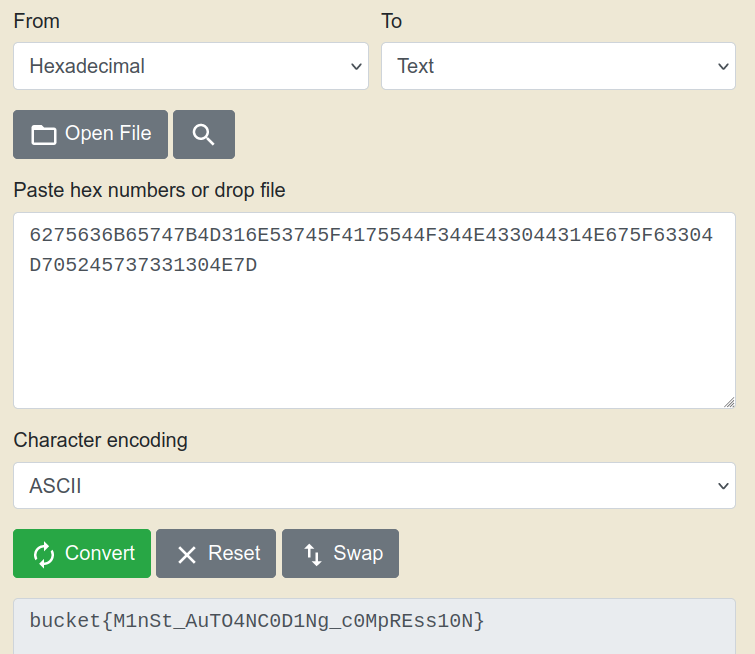
And we get the flag 🎉